
How Web Scraping Is Used To Create Headless Chrome And Puppeteer Using An Authenticated Proxy Server?

The inclusion of headless modes to Google Chromium, as well as the availability of a similar Node.js API called Puppeteer by Google previously this year, has made it exceedingly easy for developers to automate web operations like filling out forms and taking screenshots of web pages. You may use the—proxy-server command-line option to allow Chromium to utilize a custom proxy server:
chrome --proxy-server=http://proxy.example.com:8080
It's important to remember that chrome has to be an alternative for your Chromium executable (see how to do this). Because Chrome does not support the —proxy-server option in non-headless (headful?) mode, you must use Chromium instead of Chrome.
The browser will display a window inviting you to provide a username and password if the proxy server requires authentication
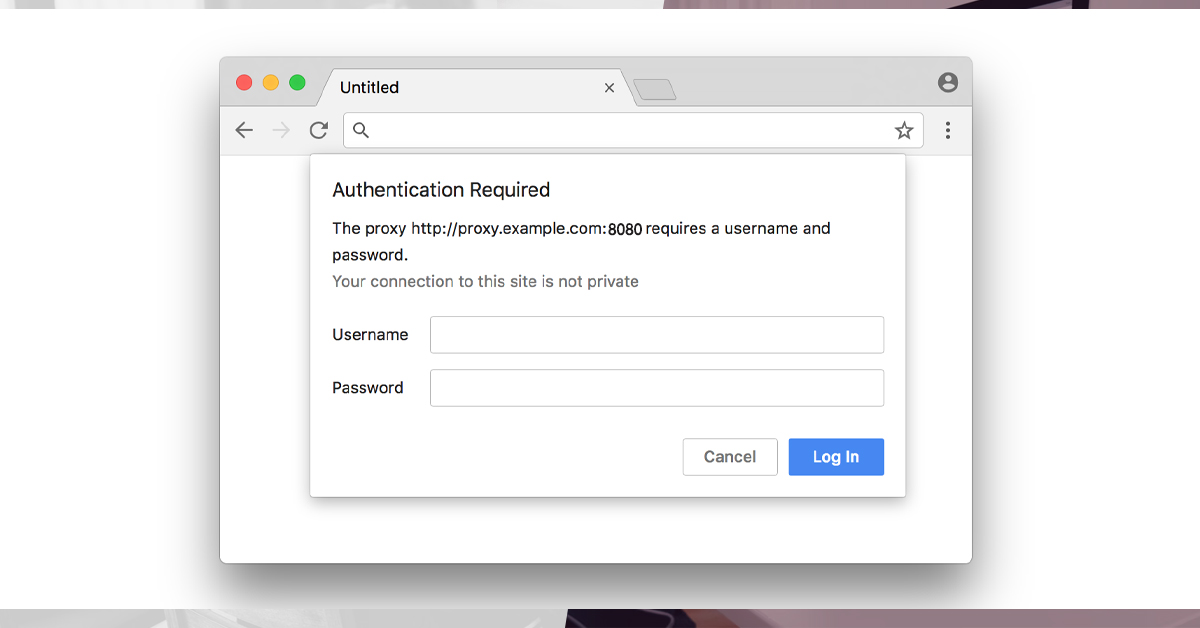
When you start Chromium in headless mode, though, you won't see this prompt since the browser doesn't have any windows. Chromium doesn't have a command-line option for passing proxy information, and neither Puppeteer's API nor the underlying Chrome DevTools Protocol (CDP) provide a mechanism to give it to the browser programmatically. It turned out that forcing headless Chromium to utilize a certain proxy account and password is not simple.
After trying
chrome --proxy-server=http://John_Doe:123@[email protected]:8080
To get around Chromium's constraint, you may set up an open local proxy server that forwards data to an upstream authorized proxy, and then tell Chromium to accept it. Squid and its cache peer configuration option can be used to build such a proxy chain. The following is an example of a Squid configuration file (squid.conf):
http_port 3128cache_peer proxy.example.com parent 8080 0 \ no-query \ login=John_Doe:123@Pass! \ connect-fail-limit=99999999 \ proxy-only \ name=my_peercache_peer_access my_peer allow all
Execute the following command to initiate squid:
squid -f squid.conf -N
Now that the proxy is running locally on port 3128, Chromium should be able to utilize it:
chrome --proxy-server=http://localhost:3128
If you wish to access it directly from your code or if you need to modify proxies on the fly, this technique becomes laborious. You'll need to either dynamically change Squid configuration or run a different Squid instance for each proxy in this situation.
Squid processes might hang or not start at all, each platform acted differently, and so on. To do something about this, we created proxy-chain, a new NPM package that we distributed as open-source on GitHub. With it, you can quickly "anonymize" an authorized proxy and then use Puppeteer to start headless Chromium using the following Node.js code:
const puppeteer = require('puppeteer'); const proxyChain = require('proxy-chain'); (async() = { const oldProxyUrl = 'http://John_Doe:123@[email protected]:8080'; const newProxyUrl = await proxyChain.anonymizeProxy(oldProxyUrl); // Prints something like "http://127.0.0.1:45678" console.log(newProxyUrl); const browser = await puppeteer.launch({ args: [`--proxy-server=${newProxyUrl}`], }); // Do your magic here... const page = await browser.newPage(); await page.goto('https://www.example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); // Clean up, forcibly close all pending connections await proxyChain.closeAnonymizedProxy(newProxyUrl, true); })();To handle protocols like HTTPS and FTP, the proxy-chain package supports both standard HTTP proxy forwarding and HTTP CONNECT tunneling. We'll be utilizing many more features in the package for our forthcoming projects, so follow us on Twitter:
If you need a proxy for web scraping service, check out Scraping Intelligence Proxy, an HTTP proxy service that allows you access to both datacenter and residential IP addresses, as well as clever IP address rotation.
Read the sample code given below:
const puppeteer = require('puppeteer'); (async() = { const proxyUrl = 'http://proxy.example.com:8080'; const username = 'John_Doe'; const password = '123@Pass!'; const browser = await puppeteer.launch({ args: [`--proxy-server=${proxyUrl}`], headless: false, }); const page = await browser.newPage(); await page.authenticate({ username, password }); await page.goto('https://www.example.com'); await browser.close(); })();Get in touch with us for any web scraping services.
Request for a quote!




